Last time we saw how people can make bad judgments about random numbers. This is because their “representation” of what random numbers should look like is wrong. In particular, we showed how people underestimate the variability in small samples of random numbers. We also showed that this can have real-world implications for the judgments we make about things like cancer clusters and school size.
Today we will investigate another way in which people’s intuitions about random numbers go awry because their representations of random numbers are flawed.
This example works better in a group demonstration and I will try it again in the Zoom for this class. However, I want to have it in the notes so you can refer back to it later. If it doesn’t make total sense on your first read through, hopefully it will make more sense after class.
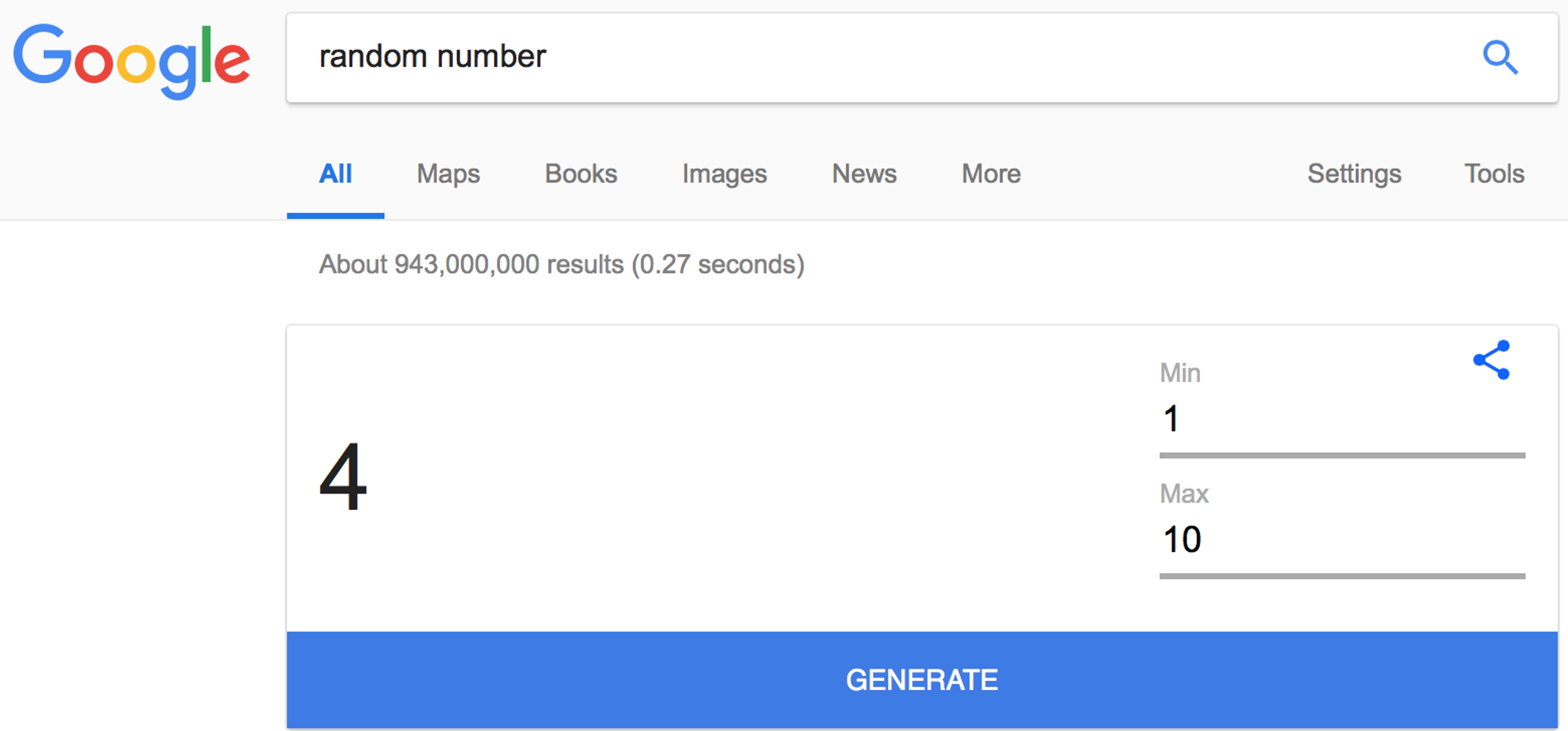
This game is all about generating random numbers. To start, please do a Google search for
random number
This should give you a tool like this, which allows you to generate a random number between 1 and 10.
Please generate a random number.
If you scored 8 or higher, you are a WINNER! Congratulations! You must be really great at generating random numbers. Now generate another one. What did you get? Hopefully you didn’t let me down … if you did you are just proving that positive reinforcement doesn’t work.
If you scored 3 or lower, you are a LOSER! I can’t believe you could do so badly at generating a random number! Now generate another one and do a better job this time. What did you get now? Hopefully you improved … if you did, you are proving that negative reinforcement does work.
Of course, the above two statements are crazy! Please don’t take them literally! I promise none of you are losers!
The point of this game is to illustrate a phenomenon known as “Regression to the Mean.” This is where abnormally high or abnormally low numbers tend to average out in the long run.
In this example, it’s clear that the number you get on the second play should be totally unrelated to the number you get on the first play. So the average on the second play will be 5.5 (average of numbers from 1 to 10).
This is illustrated in a simulated example below (with thousands of random numbers).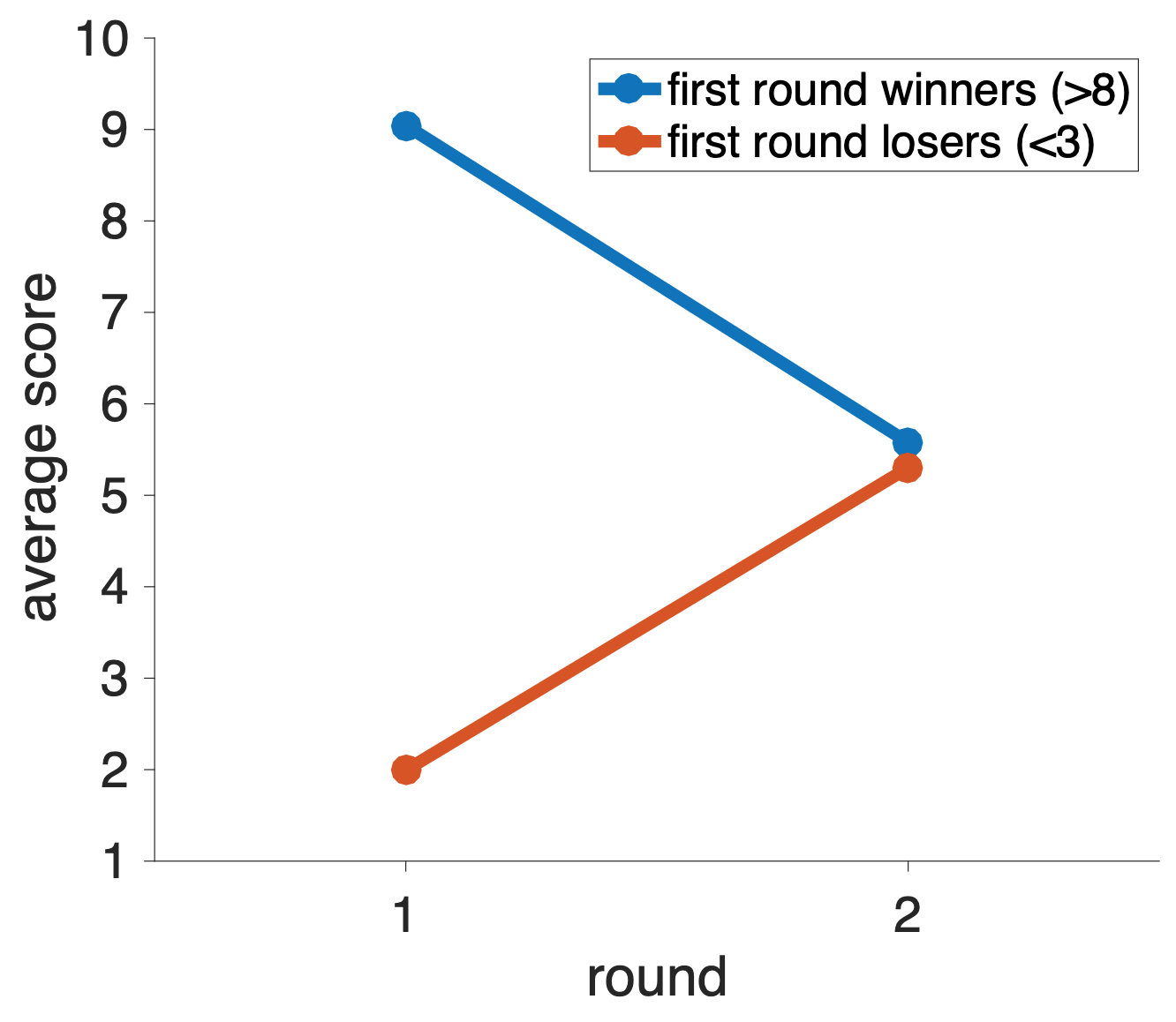
For the first round winners, their average on the first round is 9. This is not surprising since we defined these winners as having a score of 8 or more. Their average appears to “get worse” on the second round, but that’s only because they are “regressing to the mean” on the second round.
For the first round losers, their average on the first round is 2. Again this is not surprising. Their average appears to “get better” on the second round, but that’s also only because they are “regressing to the mean” on the second round.
Hopefully this example seems trivial. But as we shall see, when regression to the mean crops up in the real world it can fool even the smartest of us …

The instructors claimed that
Kahneman realized that this pattern of responses could just as easily be caused by random chance. Specifically he suggested that whether a maneuver was good or bad was purely down to luck.
In that case, if good maneuvers were largely just (good) luck, then the most likely outcome on second try was worse, just by chance.
Likewise if bad maneuvers were also largely (bad) luck, then the most likely outcome on second try was better.
In both cases, the feedback from the instructor was irrelevant. The outcome of the maneuver was luck both times. It’s just that if, by chance you have good or bad luck the first time, the next time you will be more likely to be average, which either looks like a worsening or improvement relative to the first, random outcome.
That’s not to say that instruction and feedback can’t be valuable, but that just chance could also explain the results.

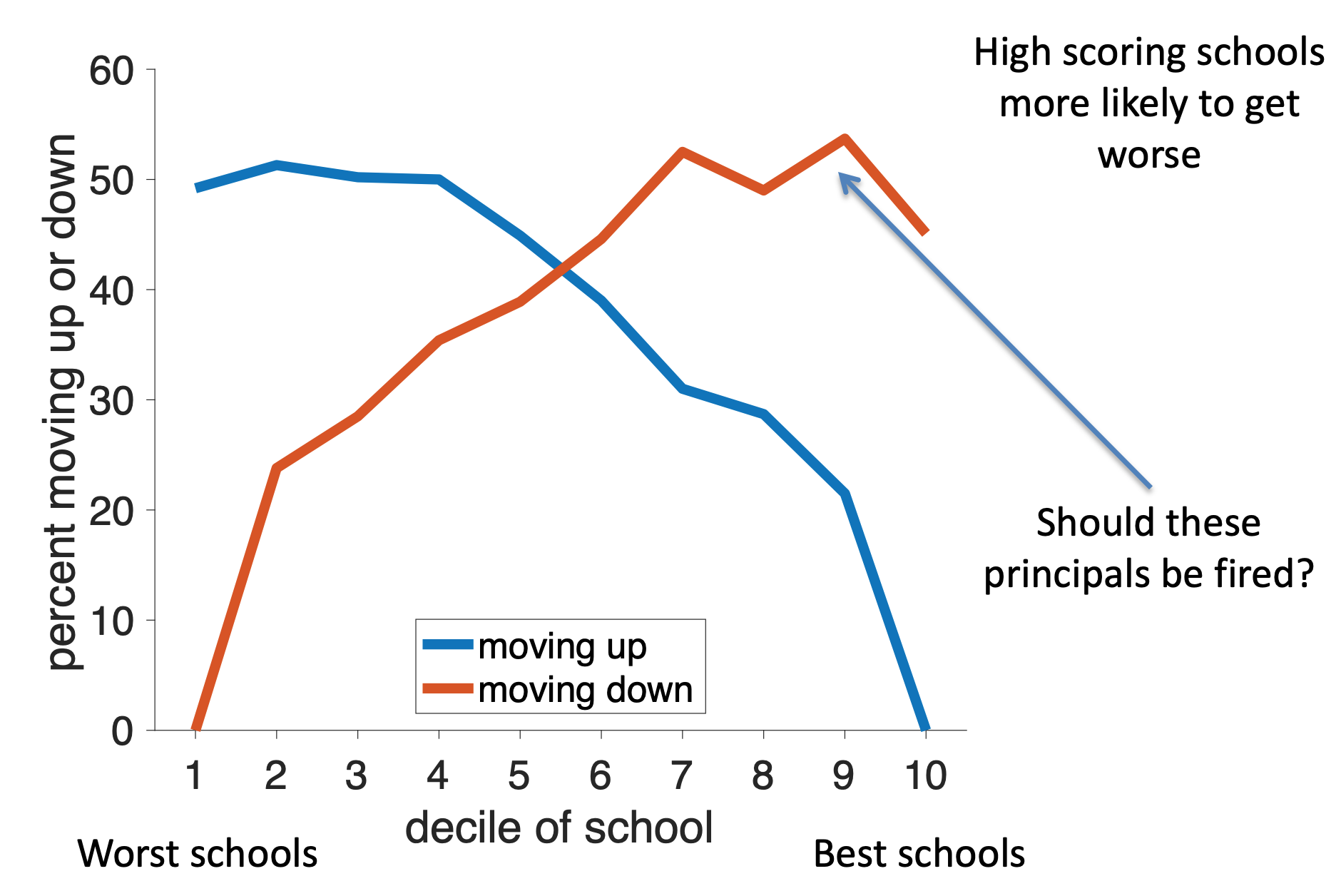
Another example comes from school test scores. A key component in evaluating schools (and the principals of those schools) is whether their test scores are increasing or decreasing over time.
But there’s a problem with evaluating this change because test scores are at least partially random. This means that a school could perform poorly one year just by chance, meaning that the next year it will likely get higher scores just by regressing to the mean.
Likewise a school could, by chance, do great one year and then look like it failed the next year, just by regressing to the mean.
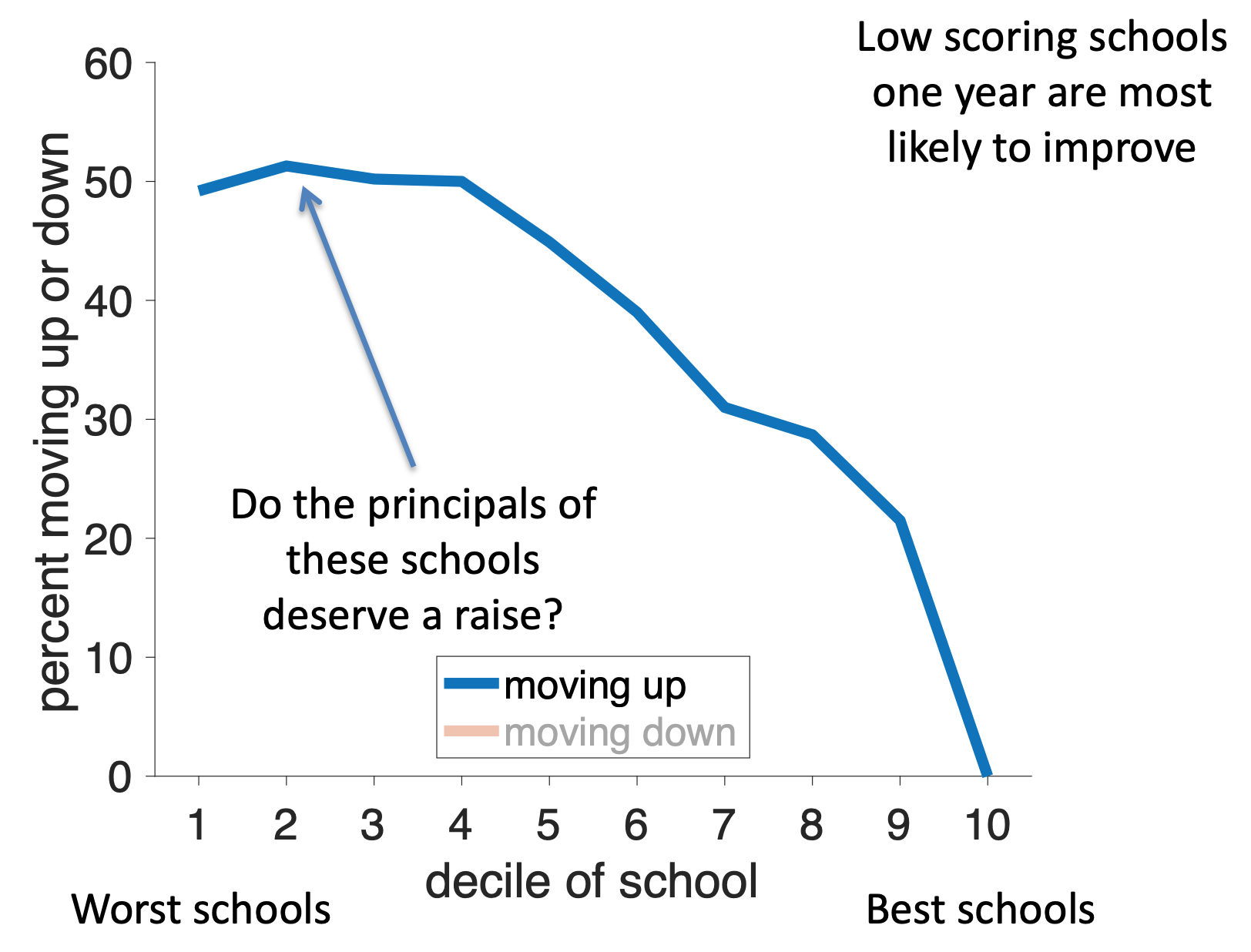
Thus regression to the mean predicts that low ranked schools should be more likely to move up next year and high ranked schools should be more likely to move down. Critically, this prediction is just a property of random numbers and is completely independent of the principal or whatever else is going on in the school!
If we plot the fraction of schools moving up in the ranking as a function of their initial ranking, we find support for this regression to the mean hypothesis. The lowest ranked schools have a 50% chance of moving up in the rankings next year, but the higher ranked schools have much lower chance of moving up. (Of course they very highest ranked schools can’t move up!)
Looking at schools that move down (red line), we see these are more likely to be schools that were initially ranked highly. Again supporting the idea of regression to the mean.